Synthesizer V 引擎
基于人工神经网络和拼接合成的混合算法,Synthesizer V仅使用少量采样数据即能生成自然的声音。我们研发的LLSM (底层语音模型) 技术分离处理声带和声道特征,从而实现对歌声音色的高保真、灵活修改。
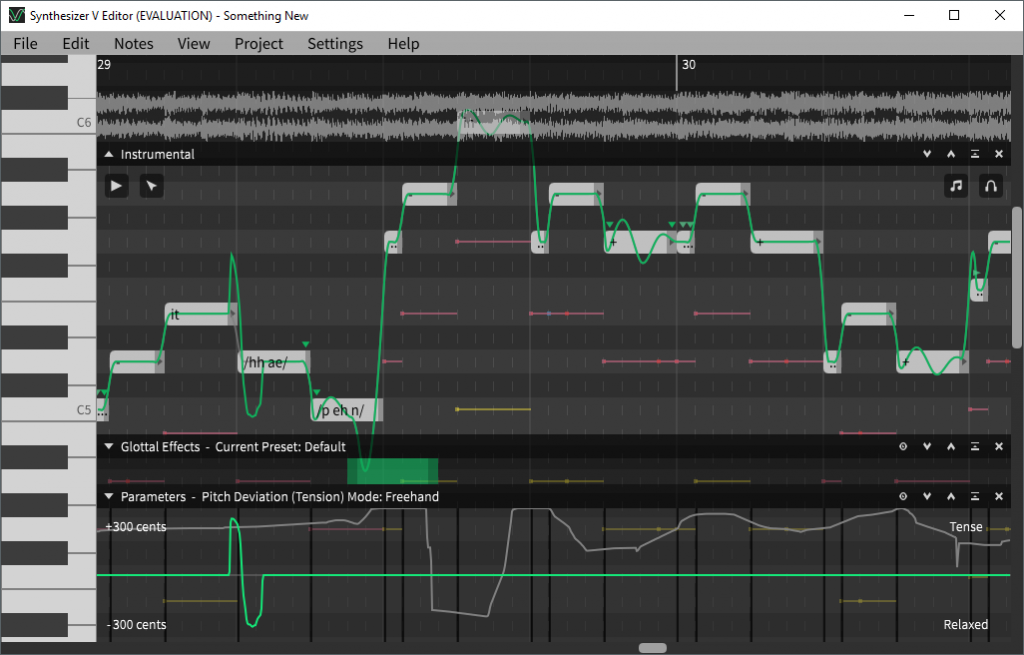
功能 最大工作区域 编辑器的设计原则是在保持简洁的同时最大化工作效率。为此,我们把整个窗口分配给钢琴卷帘;将可以最小化的面板覆盖于其上,用于显示辅助信息。半透明的设计使得面板背后被遮住的音符亦能呈现。 实时音高预览 音高变动既可以通过弹出面板,对音符逐一编辑;亦可以作为包括张力、气声在内的连续参数进行编辑。编辑器将音高曲线 (包括颤音) 可视化呈现,并实时更新音高预览。 智能歌词编辑 内建的自然语言处理模块能够理解单词和发音符号。在中文和日文下,歌词可以通过汉字、假名录入,也可以通过罗马化的拼音录入。 同步参数编辑 在"参数同步模式"下,对音符所作的修改会被同步到下方的参数中。基于此功能,参数可以随同音符一起被拖动、复制和粘贴,大幅简化了工作流程。 可定制性 所有编辑指令的快捷键都可以按照个人偏好重定义。参数面板可以从下方分离,从而和音符对齐。编辑器本身提供了多种配色方案可供选择。 多语言支持 Synthesizer V能够用美式英语、日语和汉语普通话歌唱,更多语言和方言的支持尚在计划中;编辑器已被翻译到日文、中文和韩文。
七大参数 音高偏差 实时改变实际歌声音高与书写音符音高的距离。以音分为单位,100音分为一个半音,有±300音分,±600音分,±1200音分三种模式可供选择。因此,最多可以完成上下一个八度的音高调节。默认数值为0音分。 颤音包络 实时改变颤音的深度。数值范围为音符属性中颤音深度的0倍至2倍。默认数值为1倍。 响度 实时改变歌声音量的大小。以分贝为单位,数值范围为±12dB。默认数值为0dB。 张力 实时改变虚拟歌手声带的紧张程度。以抽象的紧张、放松作为数值的上下界。在数值偏向紧张时,歌手声音明亮,坚实,有力。在数值偏向放松时,歌手气声较大,温柔。默认数值为适中。 气声 实时改变歌声气声的大小。以抽象的气声、清晰作为上下界。默认数值为适中。 发声 实时改变真实歌声(相对气声)的响度,而不影响气声的大小。以抽象的有声、无声作为上下界。在数值偏向无声时,真实歌声的音量减小,声音以气声为主。默认数值为有声。 性别 实时改变虚拟歌手音色的性别因子。以抽象的男性、女性作为上下界。在数值偏向男性时,口型偏圆,发声位置靠后,声音浑厚。在数值偏向女性时,口型偏扁,发声位置靠前,声音尖细。默认数值为适中。 运行要求 处理器 Intel Core 处理器或同等规格的 AMD 处理器 内存 1 GB 以上 操作系统 Microsoft Windows 7 及以上 (32/64 bit) / Ubuntu 16.04 及以上 (64 bit) / macOS 10.11 (El Capitan) 及以上 硬盘空间 500 MB以上



感谢分享
谢谢
棒!
用过的说下怎么样?